Metrics
Real-time metrics offer insights into your application's behaviour and performance across different environments. Each application environment displays its metrics separately.
Understanding metrics display
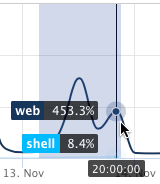
The metrics system aggregates values over time. When zooming in, values are distributed across more granular data points, revealing the actual peaks at specific moments. When zooming out, multiple peaks are aggregated, which may result in seemingly higher values.
In staging environments, only one instance per type (such as web or worker) exists. In the live environment, the number of instances varies based on the subscription. When there are multiple instances, the displayed metrics represent the cumulative values across all instances. Dividing the metric value by the number of instances provides an average value, which helps in estimating per-instance memory usage. However, this average may not reflect individual instance variations. There may be situations where a single container consumes resources disproportionately due to specific processes. In such cases, although the overall resource usage may seem normal, the overloaded container could potentially trigger errors or performance issues within the application.
In the graph, vertical lines denote deployments—green for successful ones and red for failed attempts. Spikes occurring alongside these lines highlight deployment-related activity. Additionally, spikes without accompanying lines may indicate that runners are being recycled—meaning the application is being moved to different runners. During such processes, both old and new instances run simultaneously, potentially leading to a temporary increase in resource usage. These fluctuations are typical during deployment and maintenance activities. Therefore, if you observe such increases, there's no need for concern; they are standard and usually resolve as the deployment or maintenance process concludes.
Memory metrics
The memory metric displayed represents the sum of the maximum memory usage across all containers in the environment.
Both the maximum available RAM and the number of instances running in the live environment can be adjusted in the application subscription settings.
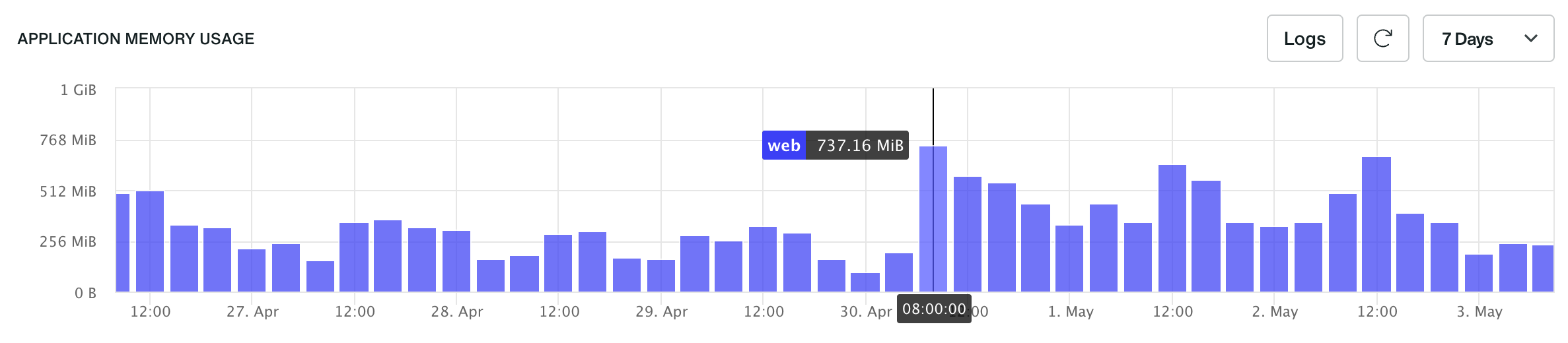
An application with 2 instances of 2GB RAM each has a total of 4GB RAM allocated. If a bar in the memory usage chart reaches 1.8GB, it suggests that, assuming an even distribution, each instance is using around 900MB. If any instance surpasses its allocated 2GB RAM, it exceeds its allocated memory. In such cases, the system uses SWAP, a mechanism that moves excess data to the hard drive. Since accessing data from the hard drive is much slower than from RAM, this can lead to decreased performance, especially during heavy swapping.
If an instance consistently exceeds its allocated RAM, the application may become slow, encounter errors, or crash. We provide SLAs to monitor and address such issues, helping to minimize unnecessary downtime.
In Unix-based systems, it's normal for memory usage to gradually increase post-deployment due to efficient memory utilization strategies like caching. However, a continuous rise without stabilization may indicate issues such as memory leaks. Monitoring these trends is essential to maintain optimal application performance and system stability.
CPU metrics
The CPU metric displayed represents the sum of the average CPU usage of each container of the given type (e.g. web, worker). The graph reflects the total number of instances available in the environment.
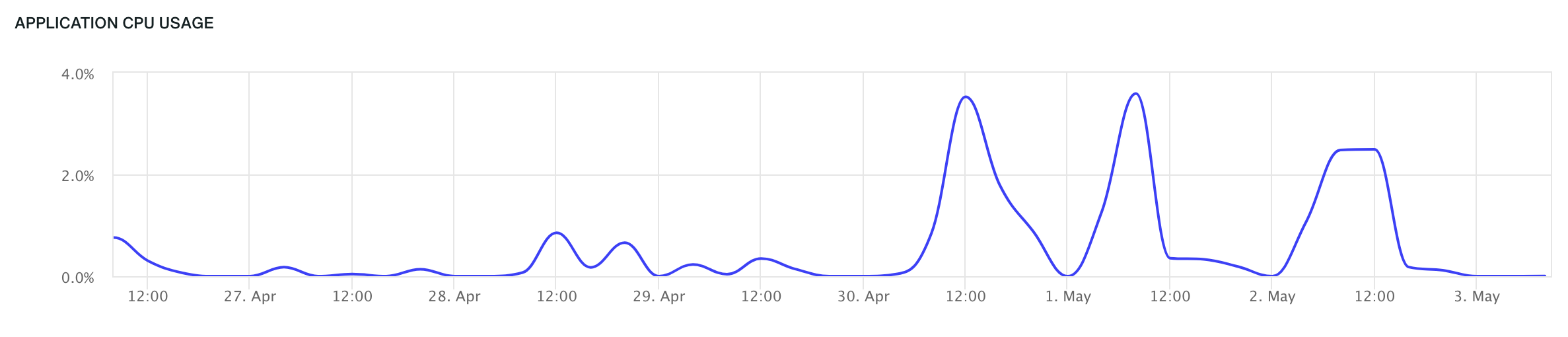
Since CPU usage metrics are aggregated over time, zooming out can produce values exceeding 100% or even 1000%. This occurs because multiple peaks are combined, resulting in higher apparent values. Zooming in provides a more accurate view, distributing values across finer time intervals, revealing the actual peaks and providing a clearer understanding of CPU consumption patterns.
In environments with multiple instances, it's possible for the total CPU usage to exceed 100%. This occurs because the displayed CPU usage represents the sum of each instance's average CPU consumption. For example, consider an application running with 3 instances, where the CPU usage is as follows:
- Instance 1:
60% - Instance 2:
56% - Instance 3:
58%
The total displayed CPU usage would be:
60% + 56% + 58% = 174%
In this scenario, the cumulative CPU usage is 174%, which exceeds 100%. This is expected because the metric aggregates the usage across all instances. The upper limit in this case would be 300% (100% per instance multiplied by 3 instances). This cumulative figure helps in assessing the overall CPU demand of the application.
It's crucial to consider individual container CPU usage, even if the overall usage appears within acceptable limits, a single container may be consuming a disproportionately high amount of CPU. For example, for an application running with 3 instances:
- Instance 1:
100% - Instance 2:
50% - Instance 3:
65% - Total:
215%(which still seems within the limit < 300%)
However, as an instance's CPU usage nears its limit, performance may decline. Exceeding this limit can cause sharp performance degradation, resulting in dropped connections and unresponsive requests due to insufficient resources.
We provide SLAs to monitor and address these issues, helping to minimize unnecessary downtime.